We Need to Talk About the Testing
In my recent session on AWS Community Day Adria 2025, I talked about real-world scenarios for building and processing messages at scale with AWS Lambda and Amazon MSK (Kafka). I called the demo “production-ready,” meaning it is deployable with some use-case tweaks and customizations. However, that is not 100% true. I did not mention anything about automated testing, which is a critical part of anything we want to call “production-ready.” To set the record straight, we will talk about testing, what the important considerations are, and finally provide an example that can be used as a reference.
The Impact of AI on Testing
We are witnessing times where AI is producing a lot of code. The impact of AI on automated testing has become very noticeable, and not always in a good way. My goal is not to criticize usage of AI, I am actually encouraging it (if done properly), but to emphasize the importance of testing and how to do it properly. The basic rules haven't changed. We need to understand the requirements, the expected outcome, and then validate it. It doesn't mean that we need to unnecessarily bloat our codebase with tests. Focus on quality, and the important parts of the solution, not on the quantity or the coverage just to make static analysis tools happy.
Documenting Tests
Sometimes, there is a misconception that documenting tests is strictly a QA responsibility if the QA team is available. This approach might be practiced in some teams, as the individual team organization is subjective and differs among companies. I disagree with this rigid approach because, in agile teams, security and quality are shared responsibilities. Developers and QA teams must become familiar with the product, understand the requirements, and work together to define test cases during sprint planning or refinements.
While there should be a clear ownership of the specific parts of the process, that does not mean that the other parts of the organization are excluded from everything. Collaboration must exist between the teams. Many companies fail at this, as ownership becomes a wall between the teams. This disconnection in the long term almost always leads to disaster or unexpected delays.
The shared responsibility model is not new or revolutionary. It is a proven way of working on a large scale. Even the lead cloud vendors, such as AWS, understand and practice this model.
Test Plan
Before implementing any automation or test scripts, let's first understand our goals and expectations. The goal is to test the provided solution for near real-time event ingestion from the Transform Lambda, through the buffer topic (Amazon MSK/Kafka), to the Write Lambda that persists data through RDS Proxy into Aurora MySQL. The tests will validate end-to-end functionality, including idempotent writes, partition-key/ordering behavior, commit-after-write semantics (offsets committed only after a successful DB write), and resilience to transient database outages.
While we are getting ready to create the test plan, let's mention that many patterns, standards, and formats exist. You should choose whatever works best for you and your team, but it is highly recommended that you set the standard and follow the same pattern throughout the organization.
Our Test Plan will consist of the following elements:
- Test Scenario
- Test Cases
- Objective (what is the purpose of testing)
- Step-by-step guide to performing the test
- Expected outcome (success result)
- Edge cases (errors)
As you will probably notice, we will test only a slice of the MSK solution I presented. The reason is that I want to keep this article short and to the point. The same principles can be applied to other parts of the solution. The important takeaway should be to understand the principles, not to build the full application.
With all this information and introduction, we are ready to create the plan for our demo.
Test Scenario
Scope: We validate the ingestion path from the Transform Lambda through the buffer topic to the Write Lambda and finally connectiig over RDS Proxy to Aurora MySQL.
Validation:
- The happy path works end-to-end.
- We are idempotent meaninng that duplicate deliveries do not duplicate rows.
- Partition key we chose provide correct ordering.
- Transient DB errors do not drop data (retry/commit).
Test Cases
Setup
We have four test cases, that represents the real-world scenario risks in this pattern. I have added option to use Redpanda instead of Kafka for local testing. The reason is that Redpanda is easy to set up, requires less resources, and is very developer-friendly. It can be used in local development or CI pipelines when testing typical flow. If you want to (or must) use Kafka, it is provided as well. The choice is yours. Pick one by setting COMPOSE_PROFILES=redpanda or COMPOSE_PROFILES=kafka environment variable. Everything else (MySQL init, ports, healthchecks) stays the same.
Test Case 1: Happy Path
Objective: Validate that a single order message is processed end-to-end successfully. Steps:
- Generate a new
orderId. - Publish one
ordermessage to the buffer topic using the Transform producer. - Let the Write consumer process the topic.
- Query the database for that
orderId.
Expected Outcome:
- The row exists with matching fields (
orderId,partnerId,status,totalAmount,currency,isDeleted) created_tsandupdated_tsare not null and are close to the current time.
Test Case 2: Idempotent Writes
Objective: In case of re-publishing the same orderId, consumer does not create duplicates and preserves creation time.
Steps:
- Generate a new
orderId. - Publish an
ordermessage. - Wait until it appears in DB.
- Capture
created_tsandupdated_ts. - Publish the same
ordermessage again (sameorderId). - Wait until
updated_tschanges in DB for thatorderId.
Expected Outcome:
- Exactly one logical row for the
orderId. created_tsremains identical.updated_tsadvances.- All business fields remain consistent.
Test Case 3: Latest Status Wins (Same Order)
Objective: Verify that later events for the same order overwrite state as expected.
Steps:
- Generate a new
orderId. - Publish
PLACEDfor thatorderId. - Wait until it appears in DB.
- Publish
CAPTUREDfor the sameorderId. - Poll the DB until the row reflects
status=CAPTURED.
Expected Outcome:
- The row’s status is
CAPTURED. created_tsremains from the first insert.updated_tsreflects the last update.
Test Case 4: Retry After DB Outage
Objective: Confirm the consumer retries on transient DB failure and no data is lost. Steps:
- Generate a new
orderId. - Stop the MySQL container to simulate outage.
- Publish an
ordermessage for thatorderId. - Wait briefly to allow initial write attempts to fail/retry.
- Start the MySQL container again.
- Poll the DB for that
orderIduntil the row appears.
Expected Outcome:
- The row eventually exists with the correct data after DB recovery.
- No message loss.
We could add a few more edge cases and validations for production, but our plan already covers a lot and resembles a real-world test plan you can reference for your projects. All the code related to this test plan is available on GitHub for your convenience to test and try. Let’s run it and check the outcome.
Running the Tests
git clone https://github.com/zasarafljivac/msk-qa-testing-demo
cd msk-qa-testing-demo
npm i
Pick one of the two options bellow.
Redpanda (default, lightweight)
COMPOSE_PROFILES=redpanda docker compose up -d
npm test
Kafka (heavier, more accurate for AWS MSK)
The reason we are setting KAFKA_BROKER environment variable is that our default is set to Redpanda on localhost:19092.
COMPOSE_PROFILES=kafka docker compose up -d
export KAFKA_BROKER=localhost:9092
npm test
After the tests are done, you can stop and remove the containers with:
docker compose down
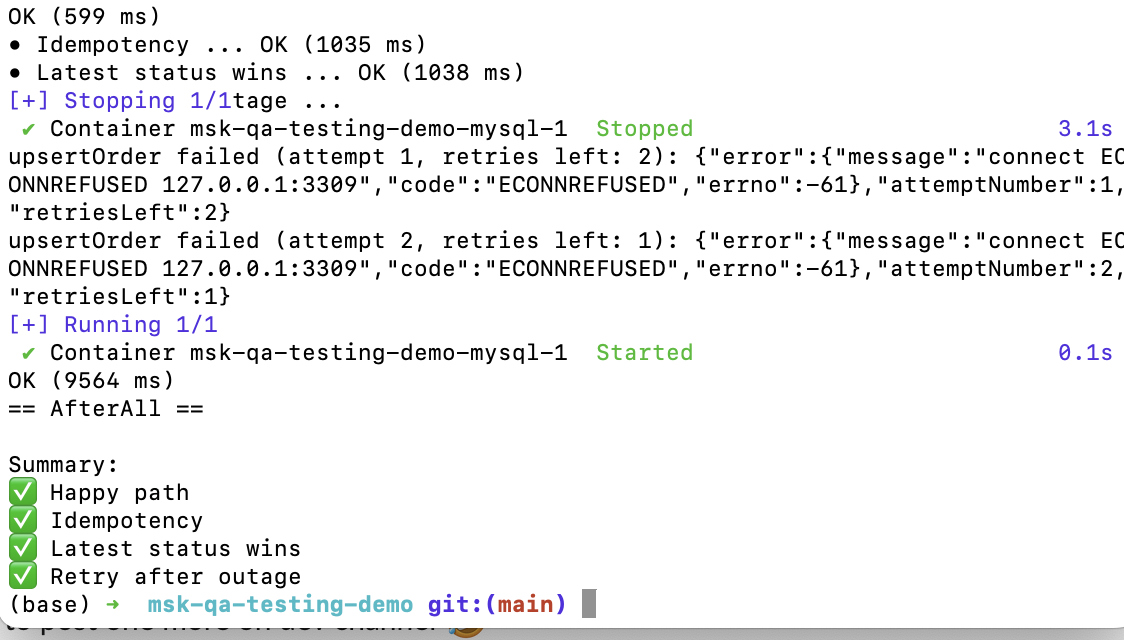 Custom Runner Output - Tests Finished Successfully
Custom Runner Output - Tests Finished Successfully
Conclusion
Believe it or not, we have reached the end. If testing feels simple, that is exactly how it should be. Your business logic is already complex enough; your tests don't have to be. As you write functions, keep asking, "How will I test this?" If the answer seems complicated or the code has too many branches, something is off. Keep functions simple so the tests can be simple and reliable.
In this short exercise, we actually covered a lot. We have developed a test plan, written test cases, and a precisely defined scope and expectations. There is no need for overthinking and duplicating work. We have just followed a natural flow. Of course, there are more tests we could add, but the point should be clear by now. If this is something you are not used to, try to follow the pattern and add the missing tests.
For the wrap-up, I want to say one more thing that I am advocating a lot. Use the platform! You don’t need to reinvent the wheel, but simple problems don’t require too clever or complex libraries. Think about what you really need. If a module or framework helps, use it, but when the platform is enough, avoid extra dependencies. Here, for the tests, we just used the NodeJS built-in assert and a small custom runner, while the system under test still uses libraries like KafkaJS and mysql2. No heavyweight test framework required.
Demo repository is available on https://github.com/zasarafljivac/msk-qa-testing-demo.
Happy testing!